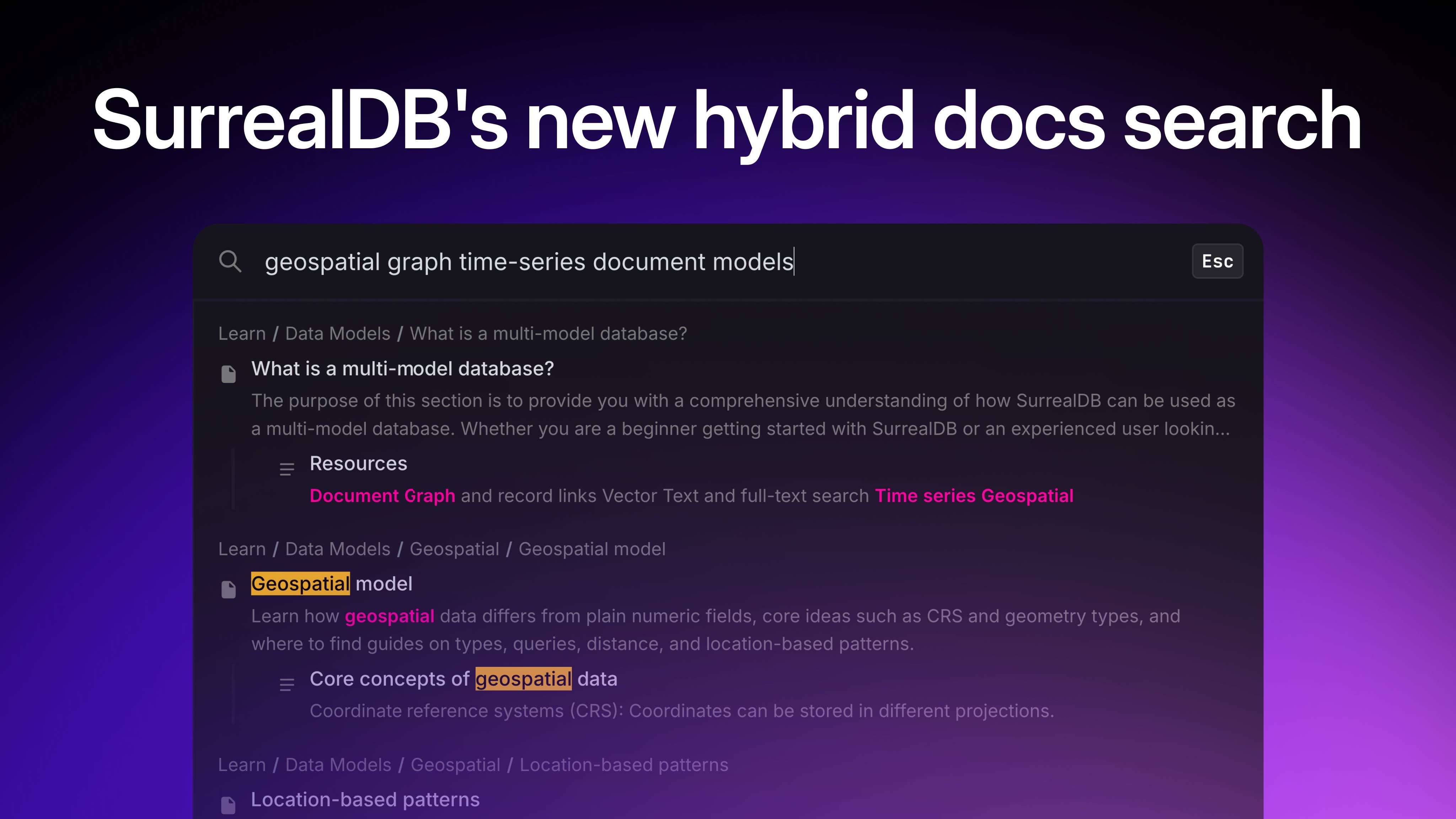
At SurrealDB, we are all about doing things that spark joy for developers ✨ One of those things that constantly surprises and delights is the humble record ID, which we discussed in our live stream.
Far from being just a boring number, your queries can be magical.
Without further ado, then, let's learn some surreal magic! ✨
The look and feel
The first thing to be aware of is that in SurrealDB, a record ID has two parts, a table name and a record identifier, which looks like this table:record.
By default, when you create a table, create internet, a random id is assigned. This differs from the traditional default of auto-increment or serial IDs you might be used to.
This allows you to avoid common problems such as:
Impact on the concurrency and scalability of your database.
Accidental information disclosure through using IDs in URLs, giving away data size and velocity.
Non-uniqueness across tables or table shards across distributed nodes
The typical solution to this is to use cryptographically secure randomly generated identifiers such as our default rand(), but you can also use ulid() and uuid().
In a nutshell, we want to make it as easy as possible to fall into the pit of success, where the default option works well as you scale.
Let's step back a bit and look at the simplest example of comparing SQL and SurrealQL, where we select one id from a table.
SQL
SELECT * FROM internet
WHERE id = 1337Just a completely run-of-the-mill example, nothing special about it.
SurrealQL
SELECT * FROM internet:leetHere we can see something new. We can filter to a record right from the from statement!
This would be the shorthand example for:
SELECT * FROM internet
WHERE id = internet:leetNow let's step it up a bit. What if we needed to select a range of ids?
SQL
-- Over 9000!
SELECT * FROM internet
WHERE id > 9000
-- less than 9000
SELECT * FROM internet
WHERE id < 9000
-- between 9000 and 10000
SELECT * FROM internet
WHERE id > 9000
AND id < 10000SurrealQL
-- Over 9000!
SELECT * FROM internet:9000..
-- less than 9000
SELECT * FROM internet:..9000
-- between 9000 and 10000
SELECT * FROM internet:9000..10000However, this is much more than just some syntactic sugar!
To understand why, we need to talk a bit about algorithmic complexity... don't worry. It's not that complicated 😉
The performance at scale
In the simplest of terms, an algorithm is just a recipe for a sequence of steps (do this, then that). Therefore, algorithmic complexity (often talked about in terms of asymptotic/big O notation) is just a way to estimate how many steps are likely to be in the sequence. The fewer steps the better.
With SurrealQL, when doing CRUD with a record ID, you don't have to do a table scan, which gets slower the more data you have. This is because the algorithm most databases use for this is O(log n) instead of the O(1) key-value lookup in SurrealDB, which has near-constant performance regardless of scale.
q(80)/cheappj41mcs73armbmg.auto)
This makes working with IDs extremely fast as you scale and opens up new use cases.
The flexibility
Now it's time for some real magic ✨
q(80)/cheappj41mcs73armbm0.auto)
It's time to free your mind and rethink what is possible with an ID.
SurrealDB's Complex Record IDs support dynamic expressions, allowing parameters and function expressions to be used as values within the IDs!
This is useful in various ways, such as a time series context or ensuring locality between specific records in a table. Effectively creating clustered indexes & partitions naturally in your data as you scale with the performance of the ID lookup regardless of size!
While this does not replace traditional indexes or partitions for your data, it offers additional flexibility to model the data in a performant way.
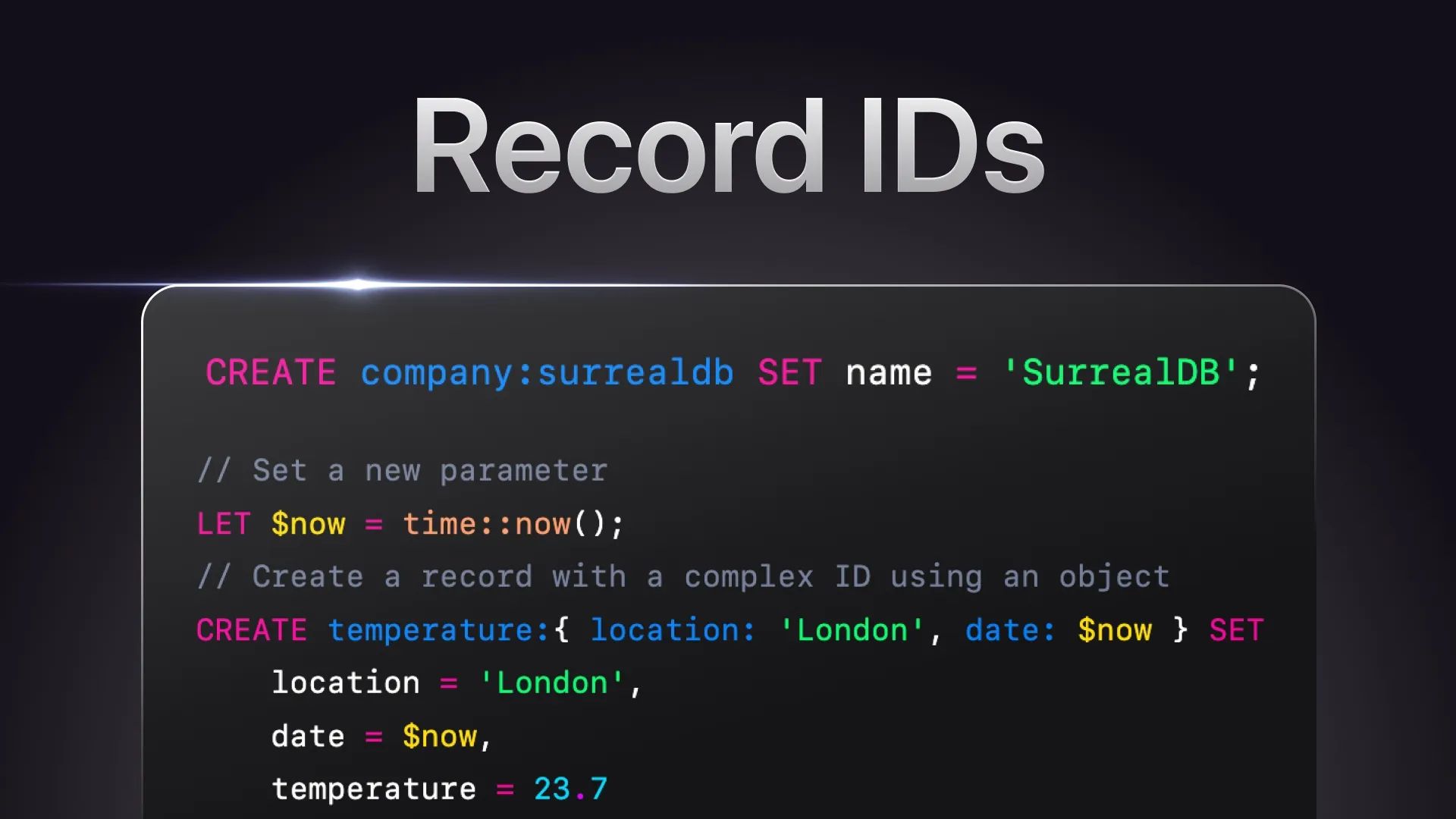
Let's look at an example of creating array-based complex record IDs:
-- Set a new parameter
LET $now = time::now();
-- Create a record with a complex ID using an array
CREATE temperature:['London', $now] SET
location = 'London',
date = $now,
temperature = 23.7
;Which you can query like this
-- Select all records for a particular location, inclusive
SELECT * FROM temperature:['London', NONE]..=['London', time::now()];
-- Select all temperature records with IDs between the specified range
SELECT * FROM temperature:['London', '2022-08-29T08:03:39']..['London', '2022-08-29T08:09:31'];
As you can see, pretty much the only limit to what a record ID can be is your imagination.
The future
We have just scratched the surface of what you can do with record IDs. If you want to dig deeper, take a look at our stream about Record IDs, featuring even more powerful capabilities, or check out our documentation.
If this has sparked some ideas, perhaps something you've always wanted was possible, we'd love to hear from you!
You'll find us at all the usual places, including our Discord and GitHub. On Discord, the #surrealql channel is the best place to get started.