In today's digital age, staying connected is easier than ever. Social media platforms allow us to remain connected with loved ones, meet new people, and stay updated on world news. However, when the urge arises to reconnect physically or explore a new destination, we go to various applications to book a flight or train effortlessly. Have you ever wondered how all these online and offline applications effortlessly search through all this complex information?
To explain that, we need to talk about the intriguing world of databases, where different data models co-exist, much like trains within a bustling metro station.
But what is a data model?
What is a data model?
A data model is essentially a conceptual framework that determines how data is structured, stored, and manipulated in a database system. It's like the blueprint of a metro station, defining how trains move, where passengers board, and where cargo gets unloaded. There are several types of data models, each designed to manage data uniquely.
Relational models
q(80)/ciuqhgaromec7399bp80.auto)
Pros
They are excellent for handling structured data and complex queries and provide robust transactional consistency (ACID properties). They also support SQL, a powerful and widely-used querying language.
Cons
They are less flexible for evolving data needs as changes to the schema can be complex and disruptive. They can be more challenging to scale, which can degrade performance.
Document models
q(80)/ciuqggqromec7399bp70.auto)
Pros
They offer high flexibility as they don't require a predefined schema. They are great for handling semi-structured or unstructured data and can scale horizontally to accommodate large amounts of data.
Cons
They are less suited to queries with complex relationships, strict schema enforcement and transactions that span multiple documents.
Graph models
q(80)/ciuqnvqromec7399bpb0.auto)
Pros
They excel in handling complex and interconnected data. They are also efficient with performing traversals and relationship-heavy queries very quickly.
Cons
They are less suited to use cases that don't involve highly interconnected data. They are also less mature than some other types of databases, and there may be fewer tools and resources available to support them.
Key-value models
q(80)/ciuqqiiromec7399bpd0.auto)
Pros
They are highly performant for read/write operations, especially when access patterns are primarily by key. They can handle large amounts of data and scale horizontally easily.
Cons
They offer limited querying capabilities, with the key generally being the only means to access data. They are also unsuited to handle complex relationships or queries across multiple keys.
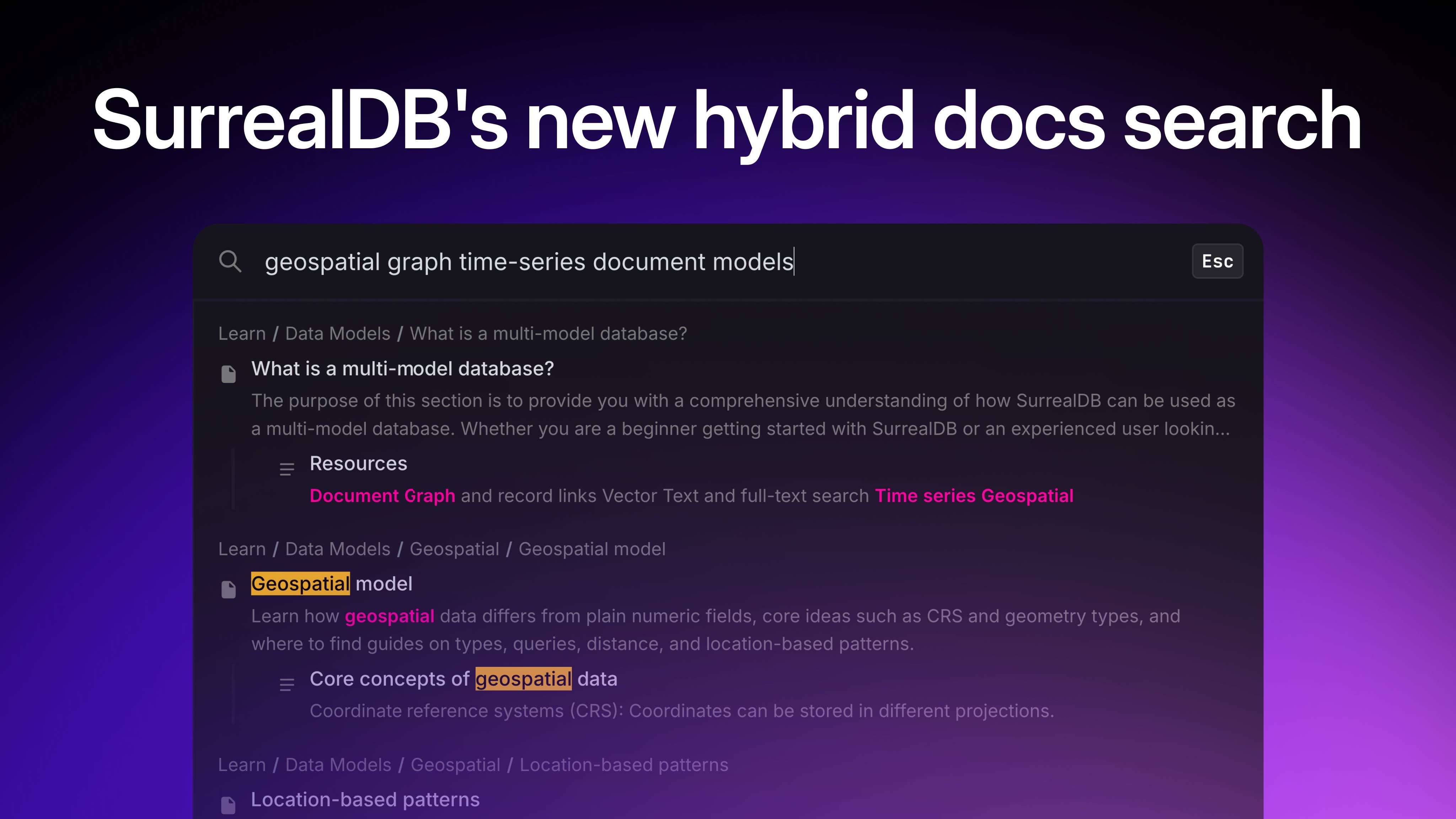
These are just some of the most commonly used models, while more data models cater to particular requirements like the time series data model, columnar data model, etc.
Are these data models enough to support today's complex applications?
The complexity of today's applications vastly differs from what it was a few years ago. Take social media platforms, for instance. They need to handle user profiles, connections, text posts, image data, and user interactions, all of which have different data requirements. Or consider an e-commerce app that deals with inventory, customer data, order history, payment details, and customer reviews.
The following query would retrieve the information about an order.
SELECT * FROM orders WHERE order_id = 123;But how would you manage semi-structured and unstructured data?
A document database can handle semi-structured or unstructured data, like product catalogues and customer reviews.
The following query would retrieve all the reviews of a particular product.
db.reviews.find({ product_id: 789 });A Graph database best handles a recommendation system based on user behaviour or interconnected data.
A query fetching the names of customers who bought a product and the name of the product they bought
MATCH (c:Customer)-[:BOUGHT]->(p:Product)
RETURN c.name as customer_name, p.name as product_nameIt is evident that a single data model can not cater to all the features of the e-commerce application or most of the advanced applications today.
Your first thought would be to use multiple databases to cater to all these needs. Polyglot persistence is a concept that advocates the use of different databases to cater to different data modelling needs in the same system.
q(80)/ciuqaoqromec7399bp50.auto)
While this approach can help you solve the problem of handling inconsistent data, it will introduce multiple challenges on the development side. Some of them would be:
Specialising in multiple database products and learning their query languages
Building a unique architecture for maintaining a relationship between these databases
System design not being reusable across multiple products
Data consistency and duplication issues across multiple databases.
Complicated deployment and frequent upgrades.
Multi-model databases provide an alternative approach that aims to solve these challenges.
What are multi-model databases?
A multi-model database is a database that has the features of multiple data models and databases built into a single database. It also has a single query language.
This query language can run queries in various ways - relational, document-based, or graph-based - depending on the most suitable approach for your current problem or the type of data stored in your database.
Whether dealing with documents, graphs, relational data, key-values, or other data formats, a multi-model database can accommodate your data, eliminating the need for complex transformations and migrations between different databases.
The beauty of multi-model databases lies in their adaptability - they mould to your data needs rather than forcing your data to adapt to a rigid structure.
Multi-model databases are often chosen as the primary database when you need to handle multiple data models and don’t want to deal with the complexity of having multiple specialised databases and traditional databases are preferred when you only need a single data model that offers the exact performance and capabilities that you are looking for; as multi-model databases might not cover all the edge cases of every data model.
SurrealDB, an innovative multi-model cloud database
SurrealDB’s architecture is built in a layered approach, effectively separating compute from storage. This facilitates individual scaling of the compute (AKA query layer) and the storage layer as required.
The query layer is responsible for handling queries from the client. It intelligently analyses which records must be selected, created, updated, or deleted.
The process involves running the SurrealQL query through a parser, an executor, an iterator, and finally, a document processor. Each component plays critical roles, from parsing the query to managing transactions, from determining which data to fetch from the storage engine to processing permissions and alterations.
On the other hand, the storage layer manages data storage for the query layer. The flexibility of SurrealDB is evident in its ability to use several underlying storage engines, each providing support for a transaction-based approach. Depending on the mode in which SurrealDB operates - embedded, distributed, or web browser - it uses different high-performing storage engines like RocksDB, TiKV, or IndexedDB, respectively.
Coming back to our e-commerce store, here’s how SurrealDB would handle all these requirements using a single query language and within the same database.
Retrieve the information about an order.
SELECT * FROM orders:123;Retrieve all the reviews of a particular product.
SELECT reviews.* FROM product:789;Fetch the names of customers who bought a product and the name of the product they bought.
SELECT name as customer_name, ->bought->product.name as product_name
FROM customerq(80)/ciuq9uqromec7399bp40.auto)
Advantages of using SurrealDB over other databases
SurrealDB is a database that does more than storing and query data. With features like Full-Text search, live queries, and in-built security permissions SurrealDB can act as the complete backend layer.
Here is a non-exhaustive list of the advantages and features of SurrealDB.
SurrealDB is written in Rust! This means performance without memory issues, a robust type system for the query language, and web assembly to put the database on any device, including a browser.
Designed to run in a distributed environment from the ground up, SurrealDB uses special techniques when handling multi-table transactions and document record IDs - without table or row locks.
Owing to the size of the binary, SurrealDB can work on IoT devices and run as standalone or clustered enterprise deployments - more modes of operation than other DBs.
Advanced table-based and row-based customisable access permissions allow for granular data access patterns for different types of users. Cuts down on backend code for authentication.
Full-text indexing, with functionality to search through the full-text index on a table.
SurrealDB is truly the database for the future. It encompasses features that aim to thoroughly change the way you thought of databases. You can learn more details about the future releases and the features of SurrealDB on the website or join us live at SurrealDB World, to help shape the future of the database industry!