

SurrealDB is built around a flexible architecture that separates the query engine (compute) from the underlying storage layer. This separation allows the same database, API, and query language to run consistently across vastly different deployment environments — from embedded edge applications to globally distributed cloud clusters.
Because compute and storage are decoupled, SurrealDB can scale seamlessly as applications grow. You can start with an embedded or single-node deployment during development, then move to distributed multi-node clusters without changing application code or queries.
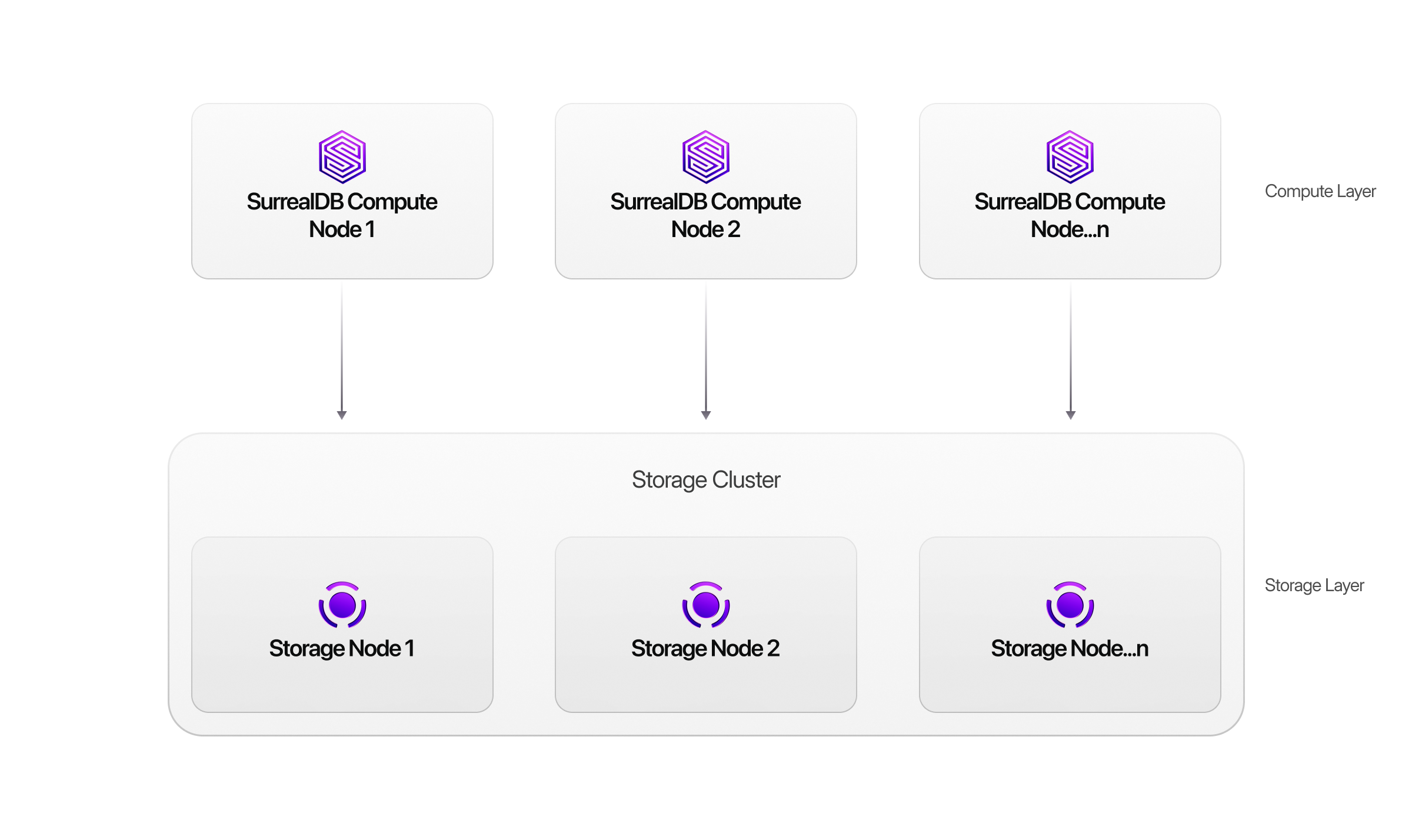
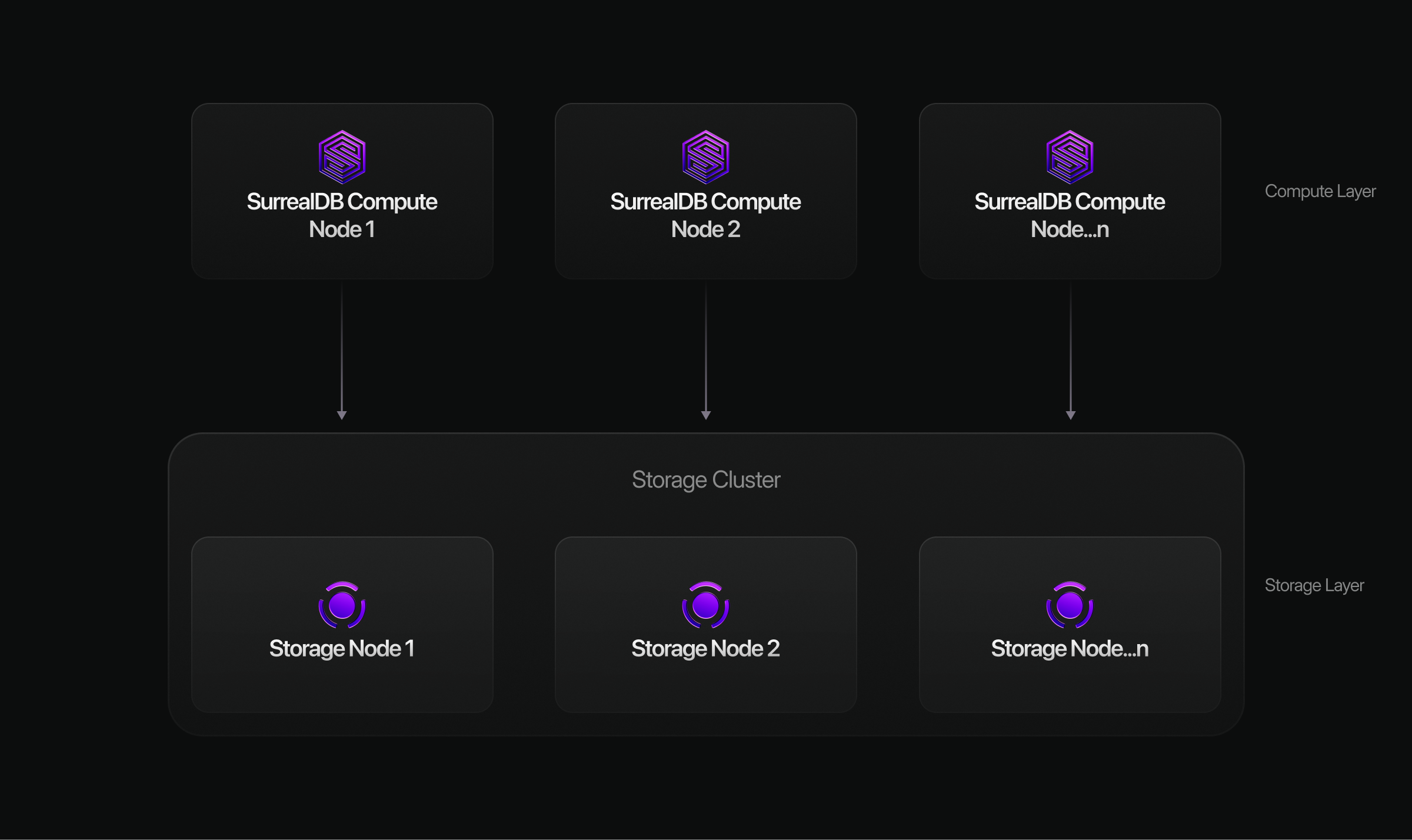
This flexibility enables SurrealDB to run wherever your application needs it:
Embedded directly inside desktop, mobile, browser, or edge applications
On a single server for production simplicity
Across distributed cloud-native clusters for high availability and horizontal scale
In fully managed environments such as SurrealDB Cloud
The result is a unified database platform that supports local-first, edge-native, and globally distributed architectures using the same developer experience everywhere.
Query layer
The query layer (compute) handles client queries and coordinates work against storage:
Parses and executes SurrealQL
Authenticates connections and sessions (for example via
SIGNINand access methods)Enforces table- and field-level
PERMISSIONSas records are read and writtenPlans index-backed queries, updates index entries on writes, and coordinates transactions against storage
At a high level, incoming SurrealQL passes through a parser, an executor that groups statements into transactions, an iterator that plans data access (including indexes) and fetches keys from storage, and a document processor that applies permissions and persists changes through the storage API. Every transaction runs under snapshot isolation with write–write conflict detection on commit, regardless of storage backend.
Storage layer
The storage layer handles persistence and durability. It determines deployment characteristics such as scalability, temporal versioning, replication, and fault tolerance. SurrealDB integrates with several engines depending on how you run the database:
Each storage engine must support transactional read and write of individual keys and key ranges so the query layer can offer consistent semantics across deployment models.
Deployment models
SurrealDB supports:
Managed deployment through SurrealDB Cloud — from single-node Start instances to multi-node Scale clusters on SurrealDS
Single-node self-hosted deployments through RocksDB (and optionally SurrealKV while in beta)
Multi-node self-hosted deployment on Kubernetes (EKS, GKE, AKS) or managed multi-node tiers on SurrealDB Cloud
Embedded deployments:
In-memory through SurrealMX
Persistent through RocksDB or SurrealKV
In the browser through IndexedDB
For deployment options, storage trade-offs, and how to choose a model, see Deployment. For isolation guarantees and concurrency behaviour, see Transactions and isolation.