

Vector search in SurrealDB
The vector search feature of SurrealDB will help you do more and dig deeper into your data. This can be used in place of, or together with full-text search.
For example, still using the same liquids table, you can store the chemical composition of the liquid samples in a vector format.
-- Insert a sample & content field into a liquids table
INSERT INTO liquidsVector [
{
sample:'Sea water',
content: 'The sea water contains some amount of lead',
embedding: [0.1, 0.2, 0.3, 0.4] },
{
sample:'Tap water',
content:
'The team lead by Dr. Rose found out that the tap water in was potable',
embedding:[1.0, 0.1, 0.4, 0.3]
},
{
sample:'Sewage water',
content: 'High amounts of a were found in Sewage water',
embedding : [0.4, 0.3, 0.2, 0.1]
}
];Notice that we have added an embedding field to the table. This field will store the vector embeddings of the content field so we can perform vector searches on it.
In the example above you can see that the results are more accurate. The search pulled up only the results in which the word "lead" was used to mean the material, while the final liquidsVector record had the lowest score. This is the advantage of using vector search over full-text search.
Another use case for vector search is in the field of facial recognition. For example, if you wanted to search for an actor or actress who looked like you from an extensive dataset of movie artists, you would first use an LLM model to convert the artist's images and details into vector embeddings and then use SurrealQL to find the artist with the most resemblance to your face vector embeddings. The more characteristics you decide to include in your vector embeddings, the higher the dimensionality of your vector will be, potentially improving the accuracy of the matches but also increasing the complexity of the vector search.
Computation on vectors: "vector::" package of functions
SurrealDB provides vector functions for most of the major numerical computations done on vectors. They include functions for element-wise addition, division and even normalisation.
They also include similarity and distance functions, which help in understanding how similar or dissimilar two vectors are.
Usually, the vector with the smallest distance or the largest cosine similarity value (closest to 1) is deemed the most similar to the item you are trying to search for.
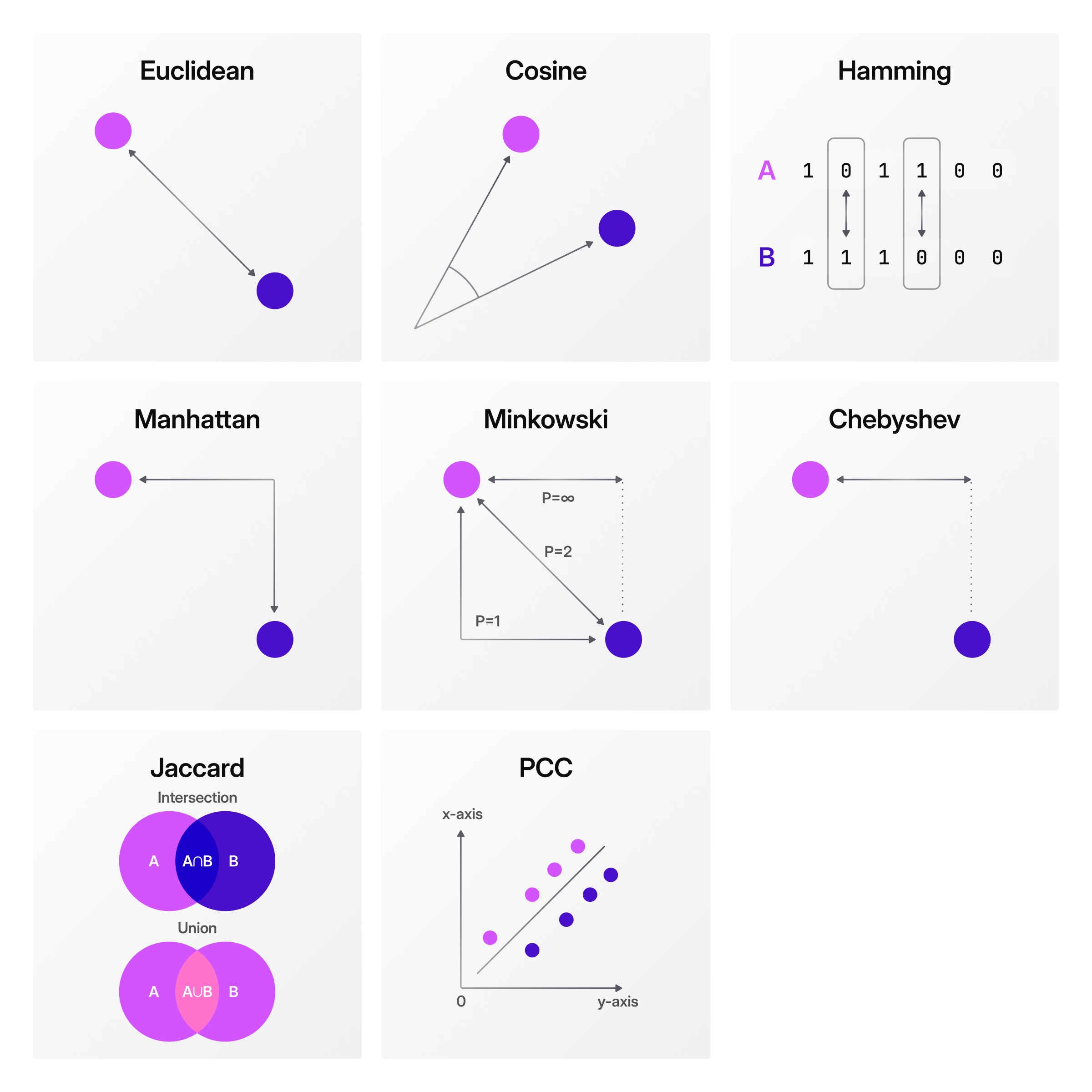
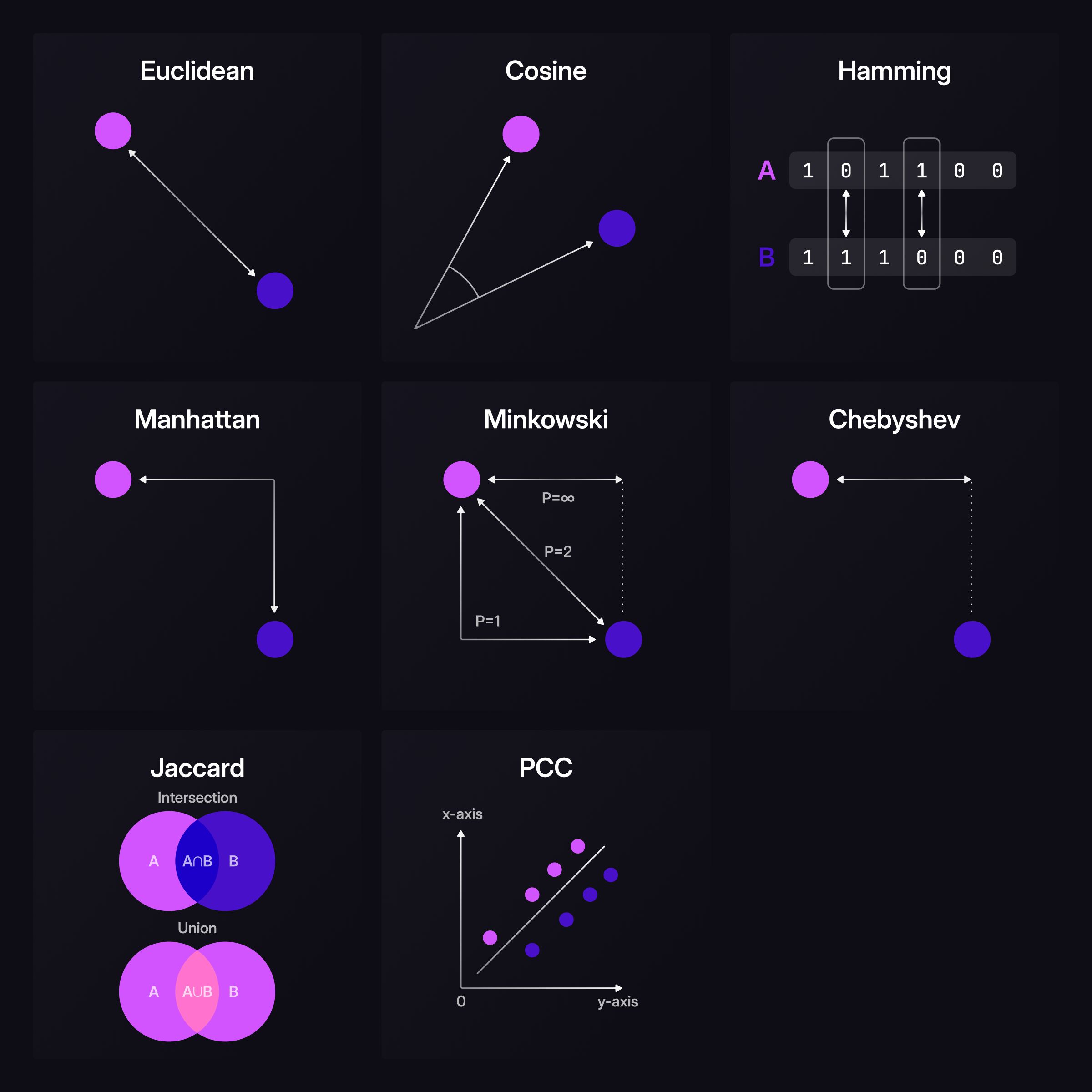
The choice of distance or similarity function depends on the nature of your data and the specific requirements of your application.
In the liquids examples, we assumed that the embeddings represented the harmfulness of lead (as a substance). We used the vector::similarity::cosine function because cosine similarity is typically preferred when absolute distances are less important, but proportions and direction matter more.
Filtering through vector search
The vector::distance::knn() function from SurrealDB returns the distance computed between vectors by the KNN operator. This operator can be used to avoid recomputation of the distance in every select query.
Consider a scenario where you’re searching for actors who look like you but they should have won an Oscar. You set a flag, which is true for actors who’ve won the golden trophy.
Let’s create a dataset of actors and define an approximate vector index on the embeddings field. This walkthrough uses HNSW; from SurrealDB 3.1 you can instead use DISKANN when your vectors no longer fit comfortably in memory. See the page on vector indexes for trade-offs and supported TYPE / DIST combinations.
-- Create a dataset of actors with embeddings and flags
CREATE actor:1 SET name = 'Actor 1', embedding = [0.1, 0.2, 0.3, 0.4], flag = true;
CREATE actor:2 SET name = 'Actor 2', embedding = [0.2, 0.1, 0.4, 0.3], flag = false;
CREATE actor:3 SET name = 'Actor 3', embedding = [0.4, 0.3, 0.2, 0.1], flag = true;
CREATE actor:4 SET name = 'Actor 4', embedding = [0.3, 0.4, 0.1, 0.2], flag = true;
-- Define an embedding to represent a face
LET $person_embedding = [0.15, 0.25, 0.35, 0.45];
-- Define an HNSW index on the actor table
DEFINE INDEX hnsw_pts ON actor FIELDS embedding HNSW DIMENSION 4;
-- Select actors who look like you and have won an Oscar
SELECT id, flag, vector::distance::knn() AS distance FROM actor
WHERE flag = true AND embedding <|2,40|> $person_embedding ORDER BY distance;[
[
{
distance: 0.09999999999999998f,
flag: true,
id: actor:1
},
{
distance: 0.412310562561766f,
flag: true,
id: actor:4
}
]
];actor:1 and actor:4 have the closest resemblance with your query vector among those who have also won an Oscar.
How the filter is applied
Because embedding is indexed, the flag = true condition is not applied after the nearest neighbours have been gathered. Instead SurrealDB pushes it down into the approximate (HNSW or DISKANN) search, so candidates that fail the condition are discarded as the graph is traversed and never occupy one of the K result slots. This keeps the result both correct, and efficient:
Correct, because you still receive up to
Krecords that match the condition.Efficient, since the search does not spend its slots on records that would only be filtered out afterwards.
Confirming the pushed-down filter with EXPLAIN
The EXPLAIN clause can be used in the same query to see the query plan. The pushed-down condition appears as a predicate attribute on the KnnScan operator:
EXPLAIN SELECT id, flag, vector::distance::knn() AS distance FROM actor
WHERE flag = true AND embedding <|2,40|> $person_embedding ORDER BY distance;'SelectProject [ctx: Db] [projections: id, flag, distance]
SortByKey [ctx: Db] [sort_keys: distance ASC]
Compute [ctx: Db] [fields: distance = vector::distance::knn(...)]
Filter [ctx: Db] [predicate: flag = true]
KnnScan [ctx: Db] [index: hnsw_pts, k: 2, ef: 40, dimension: 4, predicate: flag = true]'The predicate: flag = true on the KnnScan line is the condition being evaluated inside the index search. If the attribute is missing, the condition is not being pushed down (for example, when the vector field is not indexed). A DISKANN index produces an identical KnnScan line.
For HNSW and DISKANN configuration and the KNN cheat sheet, see Vector indexes.