

CocoIndex is an incremental indexing framework for AI agents and LLM applications. You declare what should exist in a target store — documents, embeddings, knowledge graphs — and CocoIndex keeps it in sync, reprocessing only the delta on each run.
The SurrealDB connector writes to normal tables, relation (graph edge) tables, and vector indexes. CocoIndex tracks declared records across runs: it upserts changes, skips unchanged records, and removes records that are no longer declared. Related tables in the same database reconcile inside a single atomic transaction.
How it works
Declare sources — Walk local files, S3, Google Drive, and other connectors; transform with chunking, embeddings, or LLM extraction.
Declare targets — Mount SurrealDB
TableTargetandRelationTargetstates with optionalTableSchema(SCHEMAFULL) or schemaless tables.Reconcile — On each run, CocoIndex compares the declared state with the previous run and applies upserts and deletions. Schema and vector indexes can be managed automatically when
managed_byis"system".Query — Use SurrealQL for full-text search, graph traversals, and vector similarity on the resulting data. All data can be manually queried at its namespace and database in the same way as with any other SurrealDB instance.
Key capabilities
Incremental sync — Memoised pipeline steps and target-state reconciliation avoid reprocessing unchanged inputs.
Graph-native writes — Relation tables with polymorphic
from/toendpoints map cleanly to SurrealDBRELATEedges.Schema lifecycle — Optional
TableSchemawithColumnDef; CocoIndex can define fields and drop undeclared columns on re-run.Vector indexes — Declare HNSW indexes on embedding fields; metric and dimension changes trigger index recreation. Pipelines can embed locally with
SentenceTransformerEmbedder(Rust uses FastEmbed under the hood) so you can exercise vector targets without requiring an API key.Python and Rust — Pipelines are typically authored in Python; the Rust SDK exposes the same target-state model for native binaries and examples.
Local embeddings
CocoIndex pipelines that write vectors to SurrealDB often use SentenceTransformerEmbedder — models run on your machine and download once, similar to the zero-key graph demos below. The Rust SDK loads them via FastEmbed; Python uses the sentence-transformers library with the same Hugging Face model names. The full conversation_to_knowledge example uses this for entity resolution.
To sanity-check local embeddings with SurrealDB directly — or to pick a model before you wire up a CocoIndex pipeline — see the FastEmbed integration guide. It covers ONNX models, vector dimensions, and worked examples in Python and Rust without an API key.
Podcast → knowledge graph
CocoIndex's flagship SurrealDB example is conversation_to_knowledge, in which podcast episodes become a graph of sessions, statements, people, technologies, organisations, and mention edges.
| Input | What happens |
|---|---|
input/*.txt (YouTube URLs) | yt-dlp downloads audio → AssemblyAI transcribes with speaker labels → LLM extracts claims and entities → entity resolution → SurrealDB graph |
input/*.json (pre-transcribed) | Skips download/transcription; still uses LLM extraction in the full example |
The zero-key demos below use the same interview with musician and YouTuber Rick Beato and Alice in Chains guitarist Jerry Cantrell (YouTube link) with a pre-transcribed input/sample.json. Curated statements stand in for LLM extraction so you can see reconciliation without API keys. CocoIndex does not fetch transcripts in these demos.
When connecting with Surrealist or surreal sql, use the same namespace and database your program configures — for example cocoindex / beato_cantrell, unless you set that explicitly.
Getting started
Start SurrealDB:
surreal start --user root --pass secretInstall CocoIndex with the SurrealDB extra:
pip install "cocoindex[surrealdb]"Copy input/sample.json into an input directory next to main.py. The script mounts session, statement, person, tech, and org tables plus session_statement, person_session, person_statement, and polymorphic statement_mentions relations — the same shape as the full podcast example.
export COCOINDEX_DB=/tmp/cocoindex_beato
export SURREALDB_URL=ws://127.0.0.1:8000/rpc
export SURREALDB_NS=cocoindex
export SURREALDB_DB=beato_cantrell
INCLUDE_SABBATH=1 python main.py
INCLUDE_SABBATH=0 python main.pyCOCOINDEX_DB stores CocoIndex's local change-tracking state between runs. INCLUDE_SABBATH=1 declares the Tony Iommi / Black Sabbath influence branch; setting it to 0 on the second run removes those nodes and edges.
"""Rick Beato × Jerry Cantrell → SurrealDB knowledge graph (no API keys)."""
from __future__ import annotations
import asyncio
import json
import os
from collections.abc import AsyncIterator
from dataclasses import dataclass
from pathlib import Path
from typing import Any
import cocoindex as coco
from cocoindex.connectors import surrealdb
SURREAL_DB = coco.ContextKey[surrealdb.ConnectionFactory]("surreal_db")
SESSION_ID = 100
INCLUDE_SABBATH = os.environ.get("INCLUDE_SABBATH", "1") != "0"
@dataclass
class Session:
id: int
youtube_id: str
name: str
transcript: str
description: str | None = None
date: str | None = None
@dataclass
class Statement:
id: int
statement: str
@dataclass
class Entity:
id: str
name: str
def statement_seeds(include_sabbath: bool) -> list[dict[str, Any]]:
seeds = [
{
"id": 200,
"text": "Songwriting begins with collecting riffs; most Alice in Chains songs start from a riff idea curated over time.",
"speakers": ["Jerry Cantrell"],
"persons": ["Jerry Cantrell"],
"techs": ["Riffs", "Songwriting"],
"orgs": ["Alice in Chains"],
},
# ...talk box, Seattle scene, and recording-vibe statements...
]
if include_sabbath:
seeds.append(
{
"id": 204,
"text": "Tony Iommi and Black Sabbath were foundational guitar influences; Dave Jerden helped expand Alice in Chains' studio sound.",
"speakers": ["Jerry Cantrell"],
"persons": ["Jerry Cantrell", "Tony Iommi", "Dave Jerden"],
"techs": ["Guitar tone"],
"orgs": ["Black Sabbath", "Alice in Chains"],
}
)
return seeds
@coco.lifespan
async def coco_lifespan(builder: coco.EnvironmentBuilder) -> AsyncIterator[None]:
builder.provide(
SURREAL_DB,
surrealdb.ConnectionFactory(
url=os.environ.get("SURREALDB_URL", "ws://127.0.0.1:8000/rpc"),
namespace=os.environ.get("SURREALDB_NS", "cocoindex"),
database=os.environ.get("SURREALDB_DB", "beato_cantrell"),
credentials={
"username": os.environ.get("SURREALDB_USER", "root"),
"password": os.environ.get("SURREALDB_PASS", "secret"),
},
),
)
yield
@coco.fn(memo=True)
async def declare_graph() -> None:
session_data = json.loads(Path("input/sample.json").read_text())
transcript = "\n".join(
f"({u['speaker']}) {u['text']}" for u in session_data["utterances"]
)
seeds = statement_seeds(INCLUDE_SABBATH)
session_table = await surrealdb.mount_table_target(
SURREAL_DB, "session", await surrealdb.TableSchema.from_class(Session)
)
statement_table = await surrealdb.mount_table_target(
SURREAL_DB, "statement", await surrealdb.TableSchema.from_class(Statement)
)
entity_schema = await surrealdb.TableSchema.from_class(Entity)
person_table = await surrealdb.mount_table_target(SURREAL_DB, "person", entity_schema)
tech_table = await surrealdb.mount_table_target(SURREAL_DB, "tech", entity_schema)
org_table = await surrealdb.mount_table_target(SURREAL_DB, "org", entity_schema)
session_statement = await surrealdb.mount_relation_target(
SURREAL_DB, "session_statement", session_table, statement_table
)
person_session = await surrealdb.mount_relation_target(
SURREAL_DB, "person_session", person_table, session_table
)
person_statement = await surrealdb.mount_relation_target(
SURREAL_DB, "person_statement", person_table, statement_table
)
statement_mentions = await surrealdb.mount_relation_target(
SURREAL_DB,
"statement_mentions",
statement_table,
[person_table, tech_table, org_table],
)
session_table.declare_record(
row=Session(
id=SESSION_ID,
youtube_id=session_data["id"],
name=session_data["title"],
description=session_data.get("description"),
transcript=transcript,
date=session_data.get("date"),
)
)
people: set[str] = {"Rick Beato", "Jerry Cantrell"}
techs: set[str] = set()
orgs: set[str] = set()
for seed in seeds:
statement_table.declare_record(
row=Statement(id=seed["id"], statement=seed["text"])
)
session_statement.declare_relation(from_id=SESSION_ID, to_id=seed["id"])
for speaker in seed["speakers"]:
people.add(speaker)
person_statement.declare_relation(from_id=speaker, to_id=seed["id"])
people.update(seed["persons"])
techs.update(seed["techs"])
orgs.update(seed["orgs"])
for person in seed["persons"]:
statement_mentions.declare_relation(
from_id=seed["id"], to_id=person, to_table=person_table
)
for tech in seed["techs"]:
statement_mentions.declare_relation(
from_id=seed["id"], to_id=tech, to_table=tech_table
)
for org in seed["orgs"]:
statement_mentions.declare_relation(
from_id=seed["id"], to_id=org, to_table=org_table
)
for name in people:
person_table.declare_record(row=Entity(id=name, name=name))
person_session.declare_relation(from_id=name, to_id=SESSION_ID)
for name in techs:
tech_table.declare_record(row=Entity(id=name, name=name))
for name in orgs:
org_table.declare_record(row=Entity(id=name, name=name))
app = coco.App(coco.AppConfig(name="beato_cantrell_demo"), declare_graph)
if __name__ == "__main__":
asyncio.run(app.update())For LLM extraction, entity resolution, and live YouTube ingestion, follow CocoIndex's podcast-to-knowledge-graph tutorial and the conversation_to_knowledge source. The SurrealDB connector reference covers connection setup, TableSchema.from_class, vector indexes, and relation tables in full. For local embedding models, see FastEmbed.
Inspect the graph
After either demo completes, open Surrealist with namespace cocoindex and database beato_cantrell. The schema designer shows the session-centric graph CocoIndex declared:
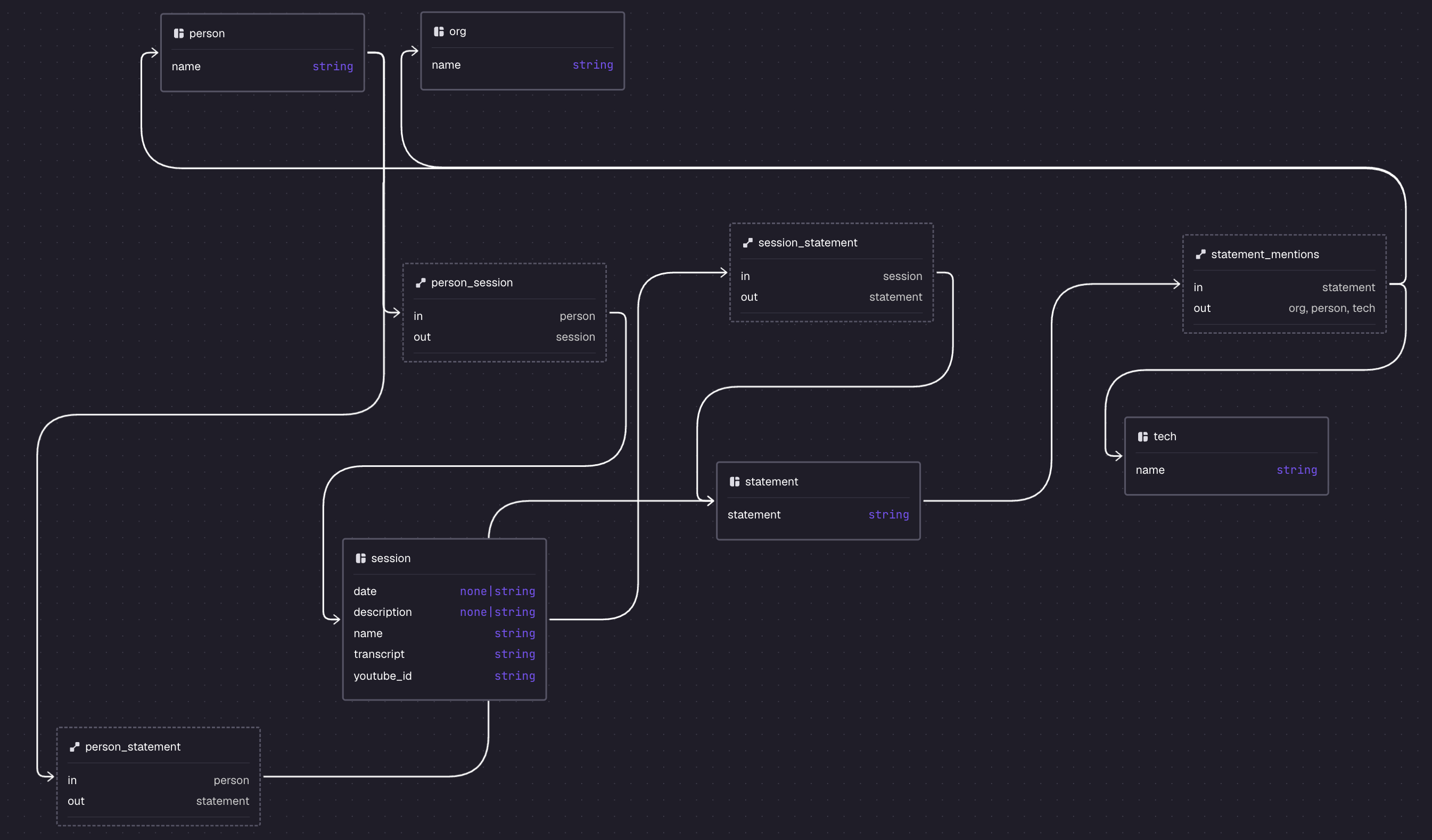
Example queries:
SELECT name FROM person;
SELECT statement FROM statement WHERE statement CONTAINS 'riff';
SELECT statement FROM statement WHERE statement CONTAINS 'talk box';
SELECT ->statement_mentions->org.name AS bands FROM statement WHERE statement CONTAINS 'Alice';After the second run (INCLUDE_SABBATH=0 in Python, or the built-in second pass in Rust), the Tony Iommi / Black Sabbath statement and its mention edges are gone — reconciliation removed anything no longer declared.
Appendix: sample.json
Create an input directory next to your demo program and save the following as input/sample.json. Utterance excerpts were polished from YouTube auto-captions for the Rick Beato × Jerry Cantrell interview.
Show input/sample.json
input/sample.json{
"id": "vBlfo0GVqqE",
"title": "Jerry Cantrell: Creating the Iconic Sound of Alice In Chains",
"channel": "Rick Beato",
"description": "Rick Beato interviews Jerry Cantrell about Alice in Chains, songwriting, guitar tones, the Seattle scene, and the solo album I Want Blood.",
"date": "2024-09-17",
"utterances": [
{
"speaker": "A",
"text": "Jerry, welcome. I'm listening to your new solo record and it has all these great riffs. Do you just sit around and put ideas on your phone? How do you keep track of everything?"
},
{
"speaker": "B",
"text": "I'm probably a collector and curator of riffs. It always starts there. Sometimes I'll hum something into a phone, but most songs begin when I stumble across a riff and think, that's cool."
},
{
"speaker": "A",
"text": "Walk me through how a riff becomes an Alice in Chains song."
},
{
"speaker": "B",
"text": "The music always comes first to me. It begins with the riff and then it develops into what I think is a piece of music that makes a great song."
},
{
"speaker": "B",
"text": "We leaned heavily on the talk box on this record — the Heil talk box and some older flavors I had not hit that hard in a while, plus a Jeff Beck-style bag talk box I had never played before."
},
{
"speaker": "A",
"text": "Let's talk about the Seattle scene when Dirt and Jar of Flies were happening."
},
{
"speaker": "B",
"text": "Seattle at that time had a real camaraderie between bands. We were all pushing each other, but Alice in Chains always put out what we wrote — no pile of unused B-sides sitting around."
},
{
"speaker": "A",
"text": "Your new solo album is called I Want Blood. How is that different from a band record?"
},
{
"speaker": "B",
"text": "It's a collaborative thing whether I'm in the band or on a solo record. There's a whole group of people and a producer — it's still a band effort, just with my name on the cover."
},
{
"speaker": "B",
"text": "It's not about perfection, it's about catching the vibe. Rock and roll is not supposed to be for everybody — it finds the people it is meant to speak to."
},
{
"speaker": "A",
"text": "Who were the guitar influences that shaped your sound?"
},
{
"speaker": "B",
"text": "Tony Iommi and Black Sabbath were huge for me early on — that dark, heavy feel. Jimmy Page too, and the way producers like Dave Jerden helped expand what we could do in the studio."
}
]
}