Architecture
This page aims to give details about some of the core architecture choices of SurrealDB, including the different layers which make up a SurrealDB instance or cluster. SurrealDB is built using a layered approach, with compute separated from storage. This allows you to scale up the compute and storage layers independently from each other, enabling support for a variety of deployment options, from embedded and edge to highly scalable self-hosted or cloud clusters.
Query layer
The SurrealDB query layer (otherwise known as the compute layer) handles queries from the client, analyzing which records need to be selected, created, updated, or deleted. To begin with, the query engine runs the SurrealQL query through a parser, returning a parsed query definition. The parsed query is then run through the executor which breaks up each statement within the query, managing those transactions which should be run within the same transaction. Next, each statement is run through the iterator which determines which data should be fetched from the key-value storage engine, and handles index query planning, grouping, ordering, and limiting. Finally, each record is passed through the document processor, processing permissions, and determining which data is merged, altered, and stored on disk.
Storage layer
The storage layer handles the storage of the data for the query layer. Each storage layer implementation stores data in an ordered list, handling storage on disk, or sharding across a cluster. SurrealDB can use a number of underlying storage engines - some support concurrent readers, and some support concurrent readers and writers. Each storage engine must support a transaction-based approach, with the ability to support reading and writing of individual keys, and key ranges within each transaction.
Deployment Options
SurrealDB supports a number of deployment models: embedded, self-hosted, or in the cloud. SurrealDB also offers a managed service, SurrealDB Cloud. The same database and API can run on all these deployment models, making it easy to sync data for architectures requiring a variety of deployment options.
For self-hosted deployments, SurrealDB supports a number of underlying storage engines depending on your scalability and fault-tolerance needs.
RocksDB
RocksDB is the most commonly used backend used to store data on disk. RocksDB is a high performance embedded database for key-value data. It is originally a fork of Google’s LevelDB optimized to exploit many CPU cores, and make efficient use of fast storage, such as solid-state drives and high-speed disk drives. It is based on a log-structured merge-tree data structure.
RocksDB is used for embedded or single-node SurrealDB deployments.
SurrealKV
SurrealKV (beta) is SurrealDB’s own storage backend, using an embedded key-value store built on an LSM (Log-Structured Merge) tree architecture, with support for time-travel queries. Time-travel queries are enacted using the VERSION clause, exclusive to SurrealKV.
TiKV
In distributed mode, SurrealDB can be configured to use TiKV to store data. TiKV is a highly scalable, low latency, and easy to use key-value datastore. TiKV supports raw and transaction-based querying with ACID compliance, and support for multiple concurrent readers and writers. The design of TiKV is inspired by distributed systems from Google, such as BigTable, Spanner, and Percolator, and some of the latest achievements in academia in recent years, such as the Raft consensus algorithm.
TiKV is used for highly scalable fault tolerant SurrealDB deployments.
Deployment architecture with TiKV
When you have deployed an HA cluster (High Availability), you will have a deployment that resembles the following configuration:
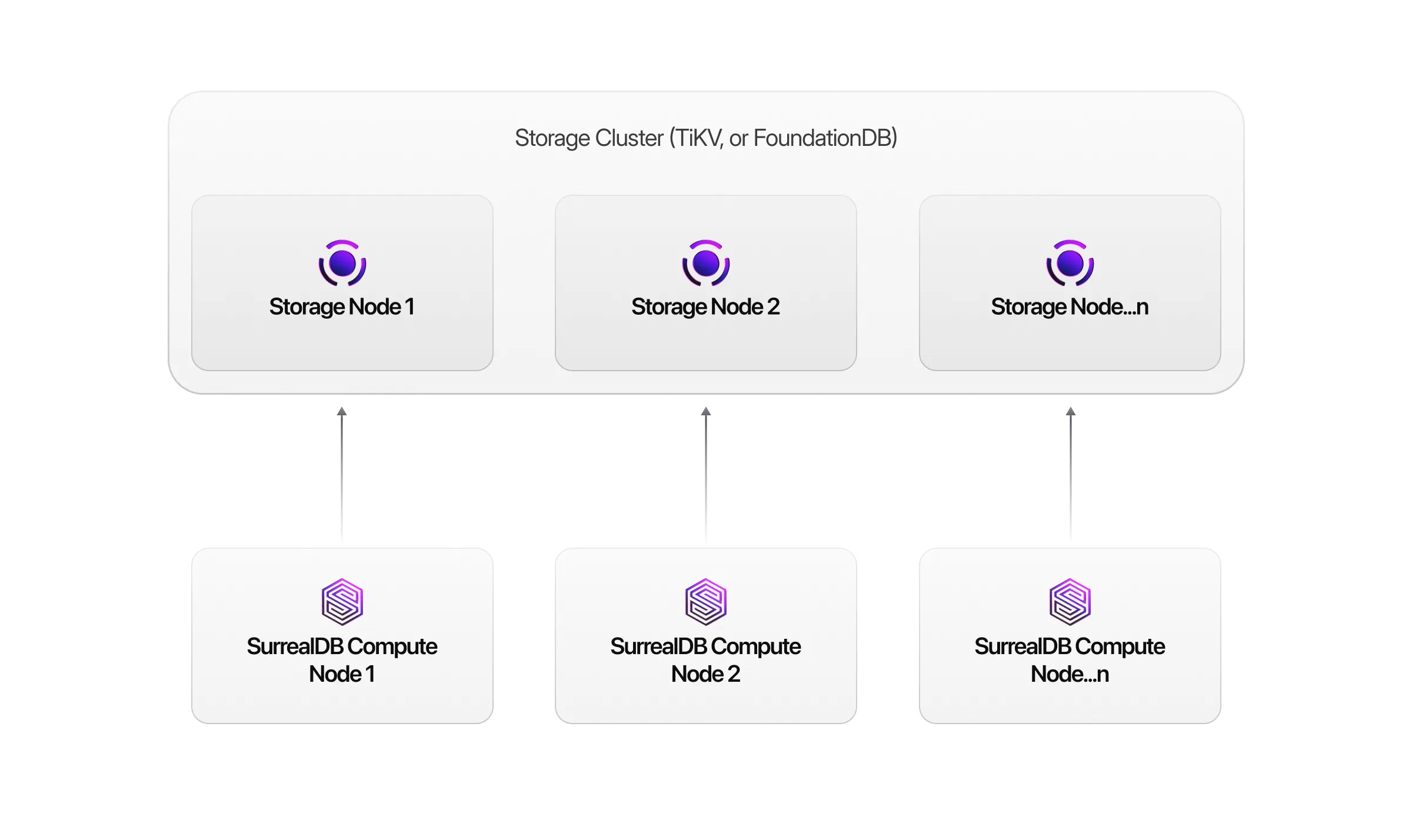
The HA deployment of your storage layer (TiKV) is the stateful part of the system. Note the following points:
- The rules governing the availability guarantees are covered in the documentation of those systems.
- SurrealDB clusters do not have state at the time of writing.
- Any necessary communication is either avoided by design, or communicated via the storage layer which maintains consistency.
This makes deploying SurrealDB convenient, since your fault tolerance is equal to the number of replicas (minus 1, the bare minimum number of instances). Though we do have bootstrapping, by design nodes can come and go as they please without much interference.
Embedded
SurrealDB can be embedded in a variety of programming languages. See Embedding SurrealDB for more information.
IndexedDB
When running in a web browser, SurrealDB can be configured to use IndexedDB to store and persist data within the web browser. SurrealDB first serializes both keys and values into a Uint8Array, utilizing IndexedDB as a binary key-value store - offering good performance, and with the ability to offer all of the functionality and features that SurrealDB offers when running in alternative ways.















