Neo4J data types are either fully supported via direct conversion, or partially supported via an object that maintains the information in the original type. For more on these data types, see the project repository.
Log in to Neo4J, start server with user neo4j and password password, then run the following queries:
Next, start a surrealdb server with the command surreal start --user root --pass root.
Then run the following command to import the data to SurrealDB:
Log in to SurrealDB under namespace test and database test, use SELECT *, friends_with->person AS friends FROM person statement to see imported data:
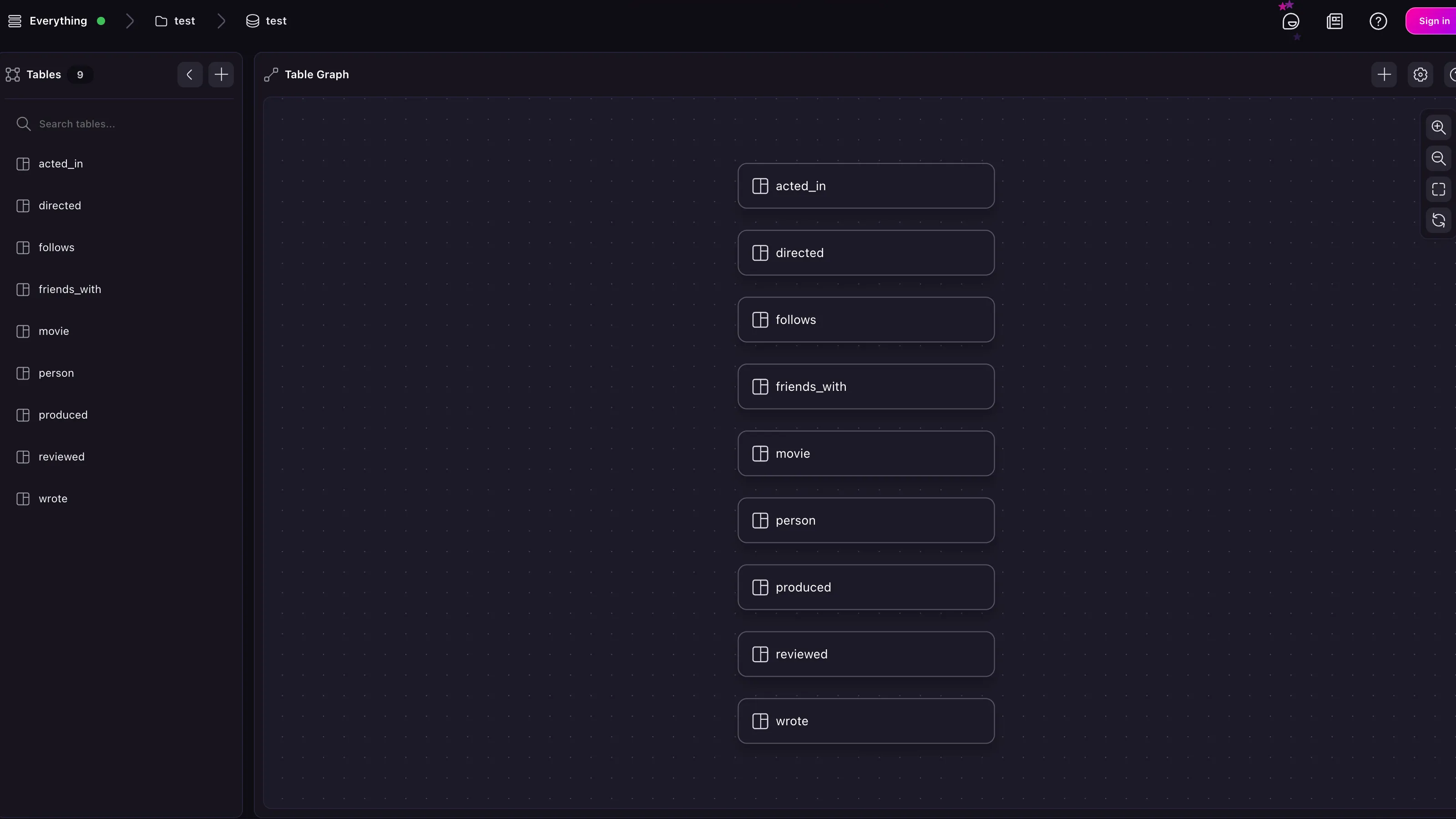
After a migration is done, you may want to add a schema. As SurrealDB is schemaless by default, tables will be declared with the DEFINE TABLE <table_name> TYPE ANY SCHEMALESS PERMISSIONS NONE. For example, if this sample movie database is imported, the Surrealist Designer view will simply show nine table names with no specified relation.
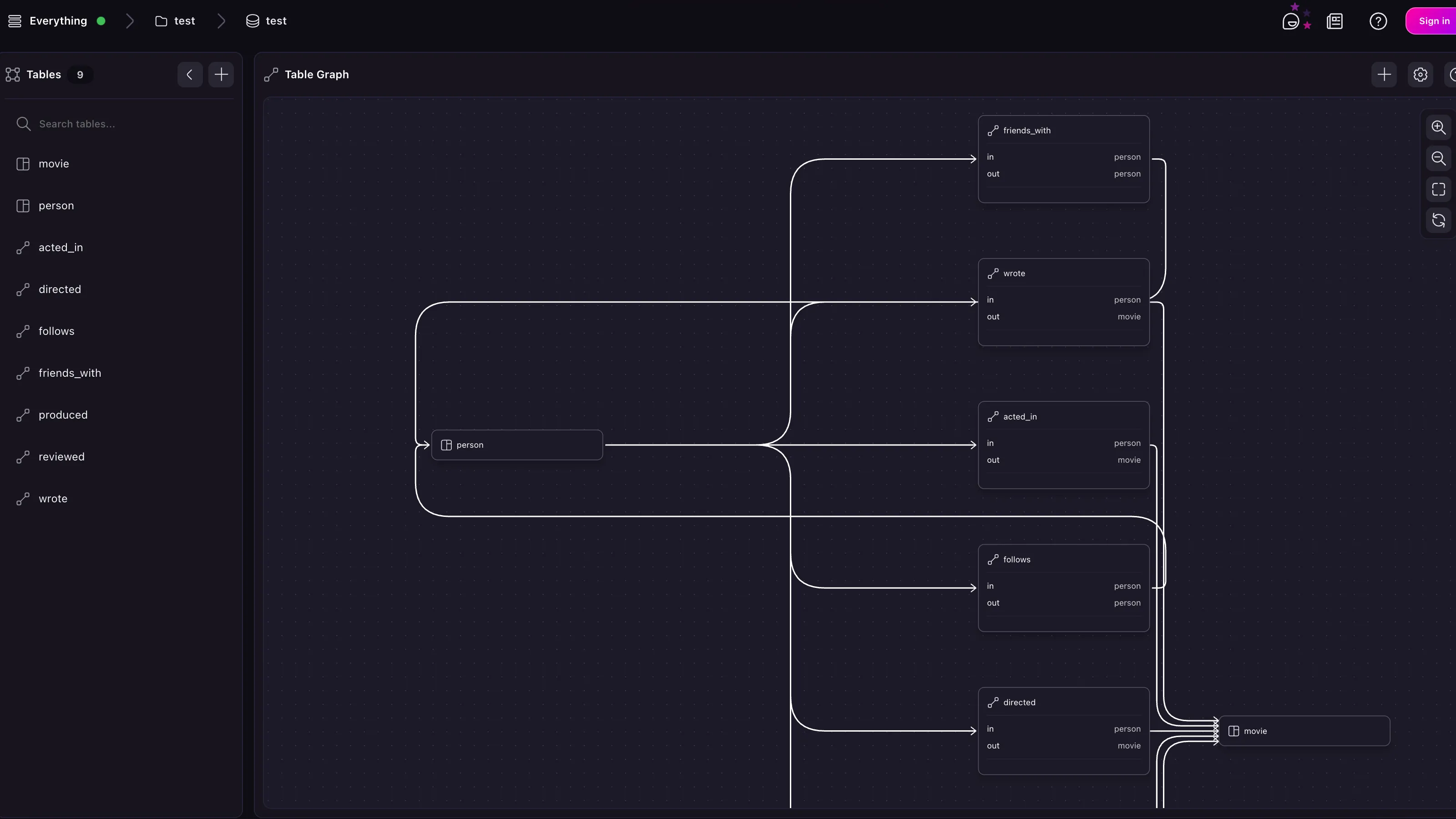
Note that the graph relations have already been set up; they just have not been strictly defined in the schema.
To begin setting a schema, you can use this sort of query to see exactly which relations exist.
This information can now be used to overwrite the existing loose definitions into concrete RELATION tables with a specified in and out.